
I would like to select manually decoding type for an opened document, but SetCurrentEncoder works only for created documents and can't find such like SetCurrentDecoder.
This is the reason why I need that:
PageStream on Amiga knows nothing about UTF-8, so we used to change some Latin-1 characters to get local characters in the font files.
But these glyphs are not the same character codes with Latin-2 or ISO-8859-16, but works well on our non unicode system (with some limitation of course as õ can be read as ő).
As PageStream is the de facto software to create printable or pdf documents this is the way how characters end in my pdf creations. To print or save as pdf is not a problem because PageStream embed the glyphs from the hacked font files.
Now I wrote a script that extracts text from PDFs, and here comes the problem.
pdf.GetText() gives back question marks both for ő and ű, so I have no chance to handle it manually.
If I change the system locale and input to latin-1, it works and I got different characters, but cannot make the change inside my script.
If I could force the decoder of GetText() that would help to read those bastards.
SetCurrentEncoder for OpenDocument
-
airsoftsoftwair

- Posts: 5450
- Joined: Fri Feb 12, 2010 2:33 pm
- Location: Germany
- Contact:
Re: SetCurrentEncoder for OpenDocument
So it renders correctly and only GetText() returns wrong characters? Can you provide a test case (PDF & script)?
Re: SetCurrentEncoder for OpenDocument
Ok, forget about the question marks. That was the MUI Royale display output.
So, yes it renders correctly and even GetText() returns the correct characters, but because the PageStream fonts are tweaked some of the characters are rendered differently as they get by GetText().
If I could change the decoder of GetText() from 8859-1 to 8859-2 then it could result the same as rendered (with the hacked fonts).
It was a quite frequent use of unlocalised fonts in this country and it was a popular solution to change the two problematic character glyphs in the fonts.
Anyway, how Polybios decide the character map of the PDF? The PDF which is generated by PageStream seems to me does not contain any codepage information.
I made a simple test script and PDF file. You can download it from here: https://kezdobetu.hu/temp/Polytest.lha.
Here is how it looks like:
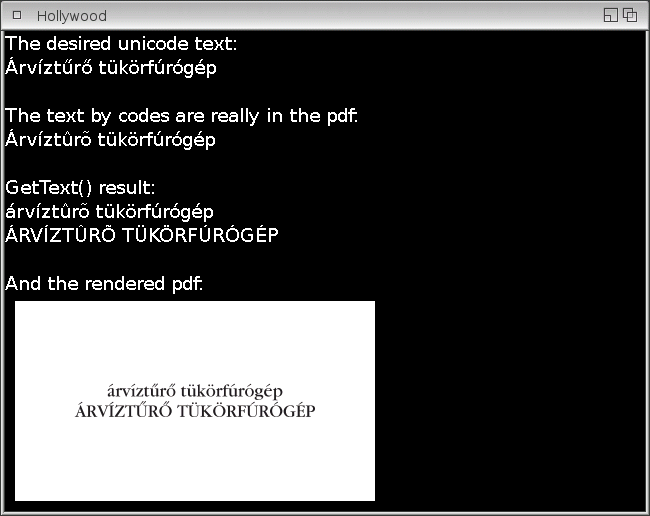
And the script:
So, yes it renders correctly and even GetText() returns the correct characters, but because the PageStream fonts are tweaked some of the characters are rendered differently as they get by GetText().
If I could change the decoder of GetText() from 8859-1 to 8859-2 then it could result the same as rendered (with the hacked fonts).
It was a quite frequent use of unlocalised fonts in this country and it was a popular solution to change the two problematic character glyphs in the fonts.
Anyway, how Polybios decide the character map of the PDF? The PDF which is generated by PageStream seems to me does not contain any codepage information.
I made a simple test script and PDF file. You can download it from here: https://kezdobetu.hu/temp/Polytest.lha.
Here is how it looks like:
And the script:
Code: Select all
@REQUIRE "polybios.hwp"
@OPTIONS {Encoding = #ENCODING_UTF8}
pdf.opendocument(1,"ps.pdf")
pdf.loadpage(1,1,True)
pdf.getbrushfrompage(1,1,1)
DisplayBrush(1,10,270,{width=4*90,height=4*50})
SetFont("DejaVu Sans",24)
NPrint("The desired unicode text:")
NPrint("Árvíztűrő tükörfúrógép\n")
NPrint("The text by codes are really in the pdf:")
NPrint("Árvíztûrõ tükörfúrógép\n")
NPrint("GetText() result:")
NPrint(pdf.gettext(1,1,0,-1))
NPrint("\nAnd the rendered pdf:")
waitleftmouse
Re: SetCurrentEncoder for OpenDocument
And just a bit of background info:
The two words "árvíztűrő tükörfúrógép" contains all of the hungarian accented letters and it translates to "floodproof mirrordriller".
The two words "árvíztűrő tükörfúrógép" contains all of the hungarian accented letters and it translates to "floodproof mirrordriller".

Re: SetCurrentEncoder for OpenDocument
Currently using: Hollywood 9 with Windows IDE and Hollywood 9 with Visual Studio Code and hw4vsc
-
airsoftsoftwair
- Posts: 5450
- Joined: Fri Feb 12, 2010 2:33 pm
- Location: Germany
- Contact:
Re: SetCurrentEncoder for OpenDocument
This is probably unfixable because the PDF doesn't contain any codepage information. The reason why it's rendered correctly is probably just because the font is embedded in the PDF.
I've just opened your PDF with Adobe Acrobat on Windows, marked all text, and pasted it into Microsoft Word. Guess what I got:
Code: Select all
árvíztûrõ tükörfúrógép
ÁRVÍZTÛRÕ TÜKÖRFÚRÓGÉP